



个人主理频道,收录推送各类项目
#开源 #网站 #AI #教程 #notion #rss
访问主页: www.noisework.cn
RSS订阅: https://tg.i-c-a.su/rss/quanshoulu
频道页面:https://tg.noisework.cn
云盘资源搜索Bot:@noisepansoubot
#开源 #网站 #AI #教程 #notion #rss
访问主页: www.noisework.cn
RSS订阅: https://tg.i-c-a.su/rss/quanshoulu
频道页面:https://tg.noisework.cn
云盘资源搜索Bot:@noisepansoubot


#AI #LLM Shinkai 是一个双击安装 AI 管理器(Ollama 与 Windows、Mac 和 Linux 兼容)。它允许您下载/使用 AI 模型、RAG,并使用工具为您执行作
https://github.com/dcSpark/shinkai-node
https://github.com/dcSpark/shinkai-node

#LLM 基于开源项目 FunClip 进行修改,集成了自动语音识别 (ASR)、说话人分离、SRT 字幕编辑以及基于 LLM 的总结功能。项目使用 Gradio 提供了一个直观易用的用户界面
https://github.com/MotorBottle/Private-ASR
https://github.com/MotorBottle/Private-ASR

#LLM 一个轻量级、支持全链路且易于二次开发的大模型应用项目 基于 Dify 、Ollama&Vllm、Sanic 和 Text2SQL 等技术构建的一站式大模型应用开发项目,采用 Vue3、TypeScript 和 Vite 5 打造现代UI。具备处理 CSV 文件 📂 表格问答的能力。同时,能方便对接第三方开源 RAG 系统 检索系统 🌐等
https://github.com/apconw/sanic-web
https://github.com/apconw/sanic-web

#AI #llm 这是一份入门AI/LLM大模型的逐步指南,包含教程和演示代码,带你从API走进本地大模型部署和微调,代码文件会提供Kaggle或Colab在线版本
https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN
https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN


#翻译 #LLM 使用大模型技术全自动翻译视频的Agent,本项目利用LLM Agent的反思机制,通过校验翻译结果控制翻译的时长,实现音视频的自动同步和高质量翻译。
经过实测,项目目前能够实现中文到英文、法文、葡萄牙文、西班牙文、德文、俄语的自动翻译,以及英文到法文、葡萄牙文、西班牙文、德文、俄语的自动翻译,其他语言暂未测试。
https://github.com/caixikai/tiktokwit?tab=readme-ov-file
经过实测,项目目前能够实现中文到英文、法文、葡萄牙文、西班牙文、德文、俄语的自动翻译,以及英文到法文、葡萄牙文、西班牙文、德文、俄语的自动翻译,其他语言暂未测试。
https://github.com/caixikai/tiktokwit?tab=readme-ov-file
#LLM #AI Agenter Daily News Collector 是一个基于开源 LLM 的自动新闻收集工作流程展示项目,由 Agently AI 应用程序开发框架提供支持。
您可以使用此项目生成几乎任何新闻收集主题。您需要做的就是简单地输入新闻收藏的字段主题。然后你等待,人工智能代理将自动完成他们的工作,直到生成高质量的新闻集合并保存到一个MD文件中。
https://github.com/AgentEra/Agently-Daily-News-Collector
您可以使用此项目生成几乎任何新闻收集主题。您需要做的就是简单地输入新闻收藏的字段主题。然后你等待,人工智能代理将自动完成他们的工作,直到生成高质量的新闻集合并保存到一个MD文件中。
https://github.com/AgentEra/Agently-Daily-News-Collector

#自动化 #LLM
Unstract 是一个开源的无代码平台,可让您自动化任何规模的文档处理工作流程。Unstract 利用尖端的 AI 超越了 IDP(智能文档处理)和 RPA(机器人流程自动化)的当前功能
官网:https://unstract.com
Github:https://github.com/Zipstack/unstract
使用Unstract,您可以实现机器对机器的自动化。你可以启动API,接收复杂的文档并返回结构化的JSON,所有这些都使用简单的无代码方法。您还可以启动非结构化数据 ETL 管道,它可以从各种云文件/对象存储系统中读取复杂文档,并将结构化数据写入常用的数据仓库和数据库。
步骤
第 1 步:将文档添加到无代码 Prompt Studio 并执行提示工程以提取必填字段 第 2 步:将 Prompt Studio 项目配置为 API 部署或为 ETL Pipeline 配置输入源和输出目标 第 3 步:将工作流部署为非结构化数据 API 或非结构化数据 ETL Pipelines!
📡发布:https://noisevip.cn/18237.html
🪧关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
Unstract 是一个开源的无代码平台,可让您自动化任何规模的文档处理工作流程。Unstract 利用尖端的 AI 超越了 IDP(智能文档处理)和 RPA(机器人流程自动化)的当前功能
官网:https://unstract.com
Github:https://github.com/Zipstack/unstract
使用Unstract,您可以实现机器对机器的自动化。你可以启动API,接收复杂的文档并返回结构化的JSON,所有这些都使用简单的无代码方法。您还可以启动非结构化数据 ETL 管道,它可以从各种云文件/对象存储系统中读取复杂文档,并将结构化数据写入常用的数据仓库和数据库。
步骤
第 1 步:将文档添加到无代码 Prompt Studio 并执行提示工程以提取必填字段 第 2 步:将 Prompt Studio 项目配置为 API 部署或为 ETL Pipeline 配置输入源和输出目标 第 3 步:将工作流部署为非结构化数据 API 或非结构化数据 ETL Pipelines!
📡发布:https://noisevip.cn/18237.html
🪧关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
#LLM #AI RAG-GPT 利用 LLM 和 RAG 技术,从用户定制的知识库中学习,为各种查询提供上下文相关的答案,确保快速准确的信息检索
https://github.com/open-kf/rag-gpt
https://github.com/open-kf/rag-gpt
#LLM #模型 ssc-FinLLM 是能够支持 金融咨询-金融nlp任务-简单金融计算--金融研判 金融链路的金融大模型,由书生·浦语2.0(InternLM2)指令微调而来
https://github.com/haidizym/ssc-FinLLM
https://github.com/haidizym/ssc-FinLLM

#LLM #AI 🚀 KIMI AI 长文本大模型免费服务,支持高速流式输出、联网搜索、长文档解读、图像解析、多轮对话,零配置部署,多路token支持,自动清理会话痕迹
https://github.com/LLM-Red-Team/kimi-free-api
https://github.com/LLM-Red-Team/kimi-free-api
#AI #LLM
Flyflow一行代码即可解锁低延迟可微调LLM模型
介绍
Flyflow是在2024年3月推出的一项针对模型微调API集成的一项服务,Flyflow 是中间件,旨在针对所有LLM的响应、延迟、安全性等进行优化,构建为开源、用 golang 编写的高性能,以及可选的自托管以实现最大的灵活性。
⚠️:截止本文发送时间该服务处于早期运行阶段
官网:https://flyflow.dev
GITHUB:https://github.com/flyflow-devs/flyflow
特征
Flyflow 使用 openai 自动跟踪您的查询模式,您可以使用它来微调 mixtral MoE 或 llama 70b,以匹配查询模式上 GPT4 的质量。
推理
Flyflow 通过在许多不同的推理提供程序之间进行负载均衡,可以大幅提高令牌限制和可靠性。
使用 anyscale、together.ai 和 fal 等提供商托管您的自定义精细模型,并使用与 GPT4 相同的质量水平来优化延迟、令牌/秒和速率限制。
这也实现了更高的可靠性,因为如果提供商发生故障,我们可以放弃回退来接载负载。
安全性和可观测性
Flyflow 还可以充当安全中间件,防止敏感信息到达推理提供者(包括 openai 和 microsoft)。
提供易于配置的插件,允许您从查询中过滤 PII,以及帮助您了解组织如何使用 LLM 的高级可观测性工具。
可配置性
Flyflow 被设计为具有极强的可配置性。后端是用 golang 编写的,旨在最大限度地提高性能,同时不影响开发人员的灵活性。
API端点可用模型
Model Name | API String | Context Length…
📡发布:https://noisevip.cn/17989.html
📢关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
Flyflow一行代码即可解锁低延迟可微调LLM模型
介绍
Flyflow是在2024年3月推出的一项针对模型微调API集成的一项服务,Flyflow 是中间件,旨在针对所有LLM的响应、延迟、安全性等进行优化,构建为开源、用 golang 编写的高性能,以及可选的自托管以实现最大的灵活性。
⚠️:截止本文发送时间该服务处于早期运行阶段
官网:https://flyflow.dev
GITHUB:https://github.com/flyflow-devs/flyflow
特征
Flyflow 使用 openai 自动跟踪您的查询模式,您可以使用它来微调 mixtral MoE 或 llama 70b,以匹配查询模式上 GPT4 的质量。
推理
Flyflow 通过在许多不同的推理提供程序之间进行负载均衡,可以大幅提高令牌限制和可靠性。
使用 anyscale、together.ai 和 fal 等提供商托管您的自定义精细模型,并使用与 GPT4 相同的质量水平来优化延迟、令牌/秒和速率限制。
这也实现了更高的可靠性,因为如果提供商发生故障,我们可以放弃回退来接载负载。
安全性和可观测性
Flyflow 还可以充当安全中间件,防止敏感信息到达推理提供者(包括 openai 和 microsoft)。
提供易于配置的插件,允许您从查询中过滤 PII,以及帮助您了解组织如何使用 LLM 的高级可观测性工具。
可配置性
Flyflow 被设计为具有极强的可配置性。后端是用 golang 编写的,旨在最大限度地提高性能,同时不影响开发人员的灵活性。
API端点可用模型
Model Name | API String | Context Length…
📡发布:https://noisevip.cn/17989.html
📢关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
#LLM
Klu-LLM协作优化应用程序
Klu是一个用于协作处理提示、评估和优化LLM驱动的应用程序,可加快原型完成、助手和工作流。跟踪更改并集成到您的产品开发工作流程中。Klu 与您首选的模型提供程序集成,并连接来自不同来源的数据,为您的应用程序提供独特的上下文。它提供了对 Anthropic Claude 2 和 OpenAI GPT-4 等 LLM 的统一 API 访问,使开发人员能够快速测试提示工程和性能
官网:https://klu.ai
📡发布:https://noisevip.cn/17920.html
📢关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
Klu-LLM协作优化应用程序
Klu是一个用于协作处理提示、评估和优化LLM驱动的应用程序,可加快原型完成、助手和工作流。跟踪更改并集成到您的产品开发工作流程中。Klu 与您首选的模型提供程序集成,并连接来自不同来源的数据,为您的应用程序提供独特的上下文。它提供了对 Anthropic Claude 2 和 OpenAI GPT-4 等 LLM 的统一 API 访问,使开发人员能够快速测试提示工程和性能
官网:https://klu.ai
📡发布:https://noisevip.cn/17920.html
📢关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
#LLM Chocolate Factory 是一款开源的 LLM 应用开发框架,旨在帮助您轻松打造强大的软件开发 SDLC + LLM 生成助手。无论您是需要生成前端页面、后端 API、SQL 图表,还是测试用例数据,Chocolate Factory 都能满足您的需求。
https://github.com/unit-mesh/chocolate-factory
https://github.com/unit-mesh/chocolate-factory

#AI #LLM
开源LLM工程平台
介绍
Langfuse 是一个开源的 LLM 工程平台,可帮助团队协作调试、分析和迭代其 LLM 应用程序。
官网:https://langfuse.com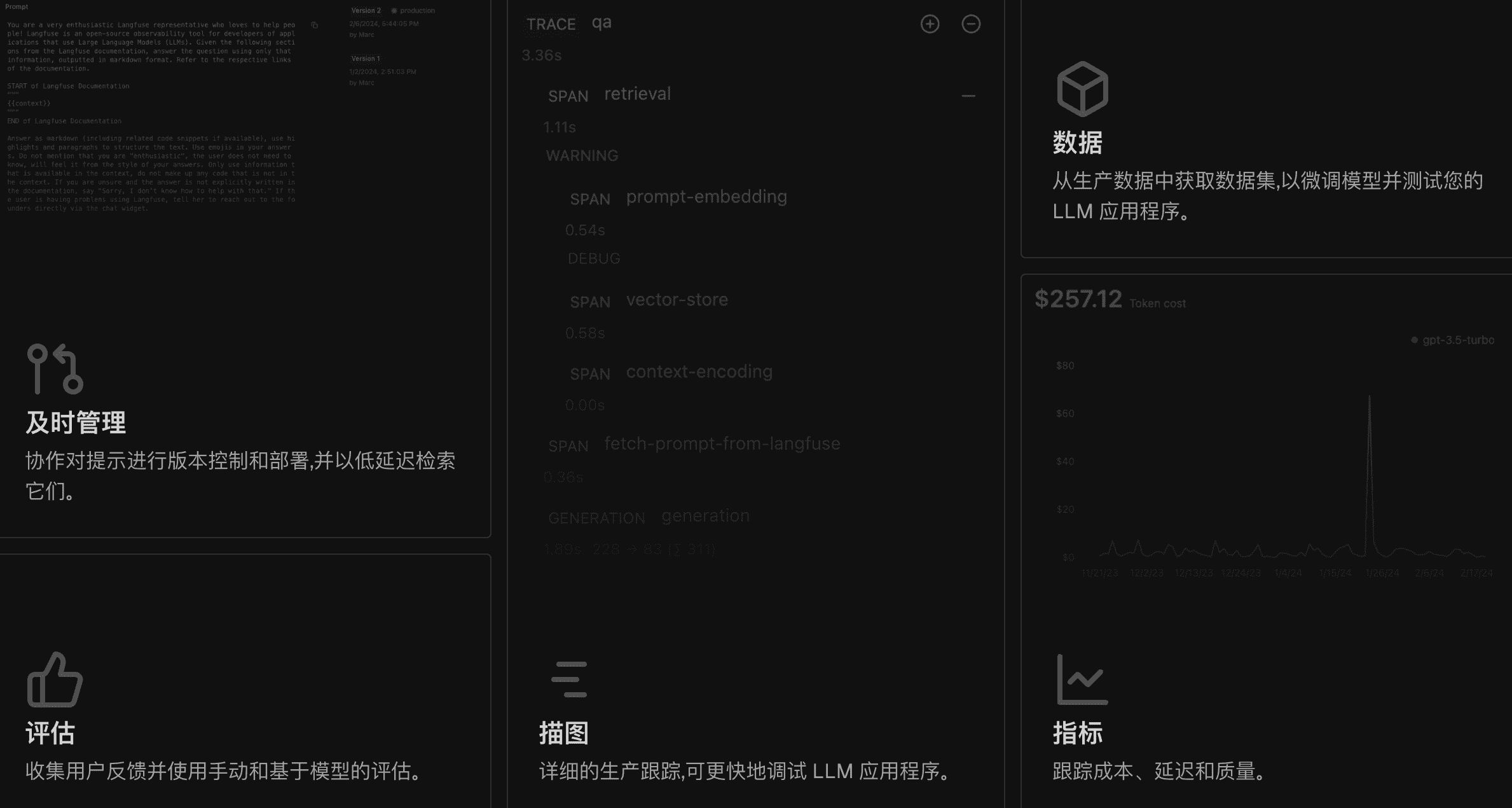
核心平台功能
发展
- **可观察性:**检测应用并开始将跟踪引入到 Langfuse(快速入门、跟踪
)
◦ 跟踪应用中的所有 LLM 调用和所有其他相关逻辑
◦ 适用于 Python 和 JS/TS 的异步 SDK,以及应用程序接口(在新选项卡中打开)
◦ OpenAI SDK、Langchain、LlamaIndex、LiteLLM、Flowise 和 Langflow 的集成
- **Langfuse 用户界面:**检查和调试复杂的日志和用户会话(演示、跟踪、会话))
- **提示:**在 Langfuse 中管理、版本控制和部署提示(提示管理)
-
监控
- **分析学:**跟踪指标(LLM 成本、延迟、质量)并从仪表板和数据导出(分析)中获得见解)
- **评估:**收集和计算你的LLM完成的分数(分数和评估
)
◦ 运行基于模型的评估
◦ 收集用户反馈
◦ 在 Langfuse 中手动对观测值进行评分
演示
📡发布:https://noisevip.cn/17787.html
📢关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn
开源LLM工程平台
介绍
Langfuse 是一个开源的 LLM 工程平台,可帮助团队协作调试、分析和迭代其 LLM 应用程序。
官网:https://langfuse.com
核心平台功能
发展
- **可观察性:**检测应用并开始将跟踪引入到 Langfuse(快速入门、跟踪
)
◦ 跟踪应用中的所有 LLM 调用和所有其他相关逻辑
◦ 适用于 Python 和 JS/TS 的异步 SDK,以及应用程序接口(在新选项卡中打开)
◦ OpenAI SDK、Langchain、LlamaIndex、LiteLLM、Flowise 和 Langflow 的集成
- **Langfuse 用户界面:**检查和调试复杂的日志和用户会话(演示、跟踪、会话))
- **提示:**在 Langfuse 中管理、版本控制和部署提示(提示管理)
-
监控
- **分析学:**跟踪指标(LLM 成本、延迟、质量)并从仪表板和数据导出(分析)中获得见解)
- **评估:**收集和计算你的LLM完成的分数(分数和评估
)
◦ 运行基于模型的评估
◦ 收集用户反馈
◦ 在 Langfuse 中手动对观测值进行评分
演示
📡发布:https://noisevip.cn/17787.html
📢关注频道:@quanshoulu
💬频道社群:https://www.noisework.cn/qun/
📬投稿bot:@noisewowbot
📇搜索bot:@Efficiencysearchbot
🎁访问主页: www.noisework.cn